原标题:2D图片3秒变立体 这可不是缩放那么简单
你离礁石越来越近,仿佛还有一秒就要触礁了。
不过这张动图,并不是从人类拍摄的视频里截下来的。
是Adobe放出的新魔法,把这张静态照片变出了立体感,整个过程只需要2到3秒:

这种特效处理,常常用于纪录片等视频的后期制作,名为Ken Burns Effect。
原本只是2D缩放 (下图左) ,通过对静止图像的平移和缩放,来产生视差,从而实现动画效果。

但这种3D效果 (上图右) ,不仅有平移和缩放,还有视角转换,给人更沉浸的体验。
想要实现,需要专业的设计师在Photoshop等软件中花费数个小时时间。
而且制作成本也很高,一张照片大概需要40美元至50美元 (约合人民币280元至350元)。
Adobe也登上了ACM主办的计算机图形学顶级期刊TOG,引发了大量讨论与关注。不乏有激动的网友给出“三连”:
Incredible. Amazing. Holy shit.
完全不是简单的缩放
透视原理决定,前景比背景的移动或缩放更剧烈。
所以,前景移动的时候,背景除了移动,也要跟着修复。
AI的背景修复十分自然,手法明显比“前辈”更高超:

形状有点奇怪的教堂
并且,不论背景简单复杂,AI都不怕。
比如,走到沙发跟前,沙发就挡住了后面窗户外的草地:

背景的色彩和结构都很复杂,但AI并没有蒙蔽。
如果你觉得,刚才的视角变化只是由远及近,不够复杂。那就看一眼这古老的台阶吧:

仿佛你打算走上台阶,所以正在朝着它的方向,慢慢转身。
除此之外,一条古老的走廊,你置身其中,好像正在从上仰的视角,变得平视前方。

当然,不只是风景,人像也可以处理。
比如,草地上的新娘,可以远观,也可以近距离欣赏:

就像开头说的那样,所有的变换,只靠一张静态图来完成。
这自然不是普通的缩放可以做到的:

左为普通缩放,右为3D魔法
所以,究竟是怎样的技术做到的?
三步定边界,结合上下文感知
用单个图像合成逼真的相机移动的效果要解决两个基本问题。
首先,要设置一个新的相机位置,合成新视图,并且需要准确地恢复原始视图的场景几何结构。
其次,根据预测的场景几何结构,要将新视图在连续的时间线上合成,这就涉及到去遮挡这样的图像修复手段。

研究人员们用了三个神经网络来构建处理框架。
用以训练的数据集是用计算机生成的。研究人员从UE4 Marketplace2收集了32种虚拟环境,用虚拟摄像机在32个环境中捕获了134041个场景,包括室内场景,城市场景,乡村场景和自然场景。每个场景包含4个视图,每个视图都包含分辨率为512×512像素的颜色、深度和法线贴图。

指定一张高分辨率图像,首先根据其低分辨率版本估计粗糙深度。这一步由VGG-19来实现,根据VGG-19提取的语义信息指导深度估计网络的训练,并用具有groundtruth的计算机合成数据集进行监督。如此,就能提取出原始图像的深度图。
第二个网络,是MaskR-CNN。为了避免语义失真,平行于VGG-19,用MaskR-CNN对输入的高分辨率图像进行分割,而后用分割的结果来对深度图进行调整,以确保图中的每个对象都映射到一个相干平面上。
最后,利用深度细化网络,参考输入的高分辨率图像,对提取出的粗糙深度进行上采样,确保深度边界更加精确。
之所以要采用深度细化网络,是因为裁切对象的过程中,对象很可能在边界处被撕开。
有了从输入图像获得的点云和深度图(注:点云指通过3D扫描得到的物品外观表面的点数据集合),就可以渲染连续的新视图了。
不过,这里又会出现一个新的问题——当虚拟摄像机向前移动的时候,对象本身会产生裂隙(下图中高塔右侧像被网格切开了)。

为了解决这个问题,研究人员采取了结合上下文感知修复的方法。
结合上下文信息能够产生更高质量的合成视图。上下文信息划定了相应像素在输入图像中位置的邻域,因此点云中的每个点都可以利用上下文信息来进行扩展。
具体而言,第一步,是进行颜色和深度图像修复,以从不完整的渲染中恢复出完整的新视图,其中每个像素都包含颜色,深度和上下文信息。
而后,利用图像修复深度,将图像修复颜色映射到点云中新的色调点。
重复这一过程,直到点云充分扩展,填补空隙,可以实时地呈现完整且连续的画面。

“用过都说好”
研究人员觉得好,那不算好。新方法效果如何,还是用户说了算。
于是,研究团队搞出了一个“非正式用户调研”。他们在YouTube上搜集了30个人类创造的3DKenBurns视频,将其分成“风景”,“肖像”,“室内”,“人造室外环境”四组,每组随机抽取三个视频作为样本。
8位志愿者参与到了这个测试之中。团队为每个志愿者分配了一张静态图,并提供了人类作品作为参考,要求志愿者使用新方法和AdobeAfterEffects模板、移动AppViewmee这两种KenBurns制作工具创作类似的效果。
志愿者会依据自己的主观意见评价每种工具的可用性和质量。
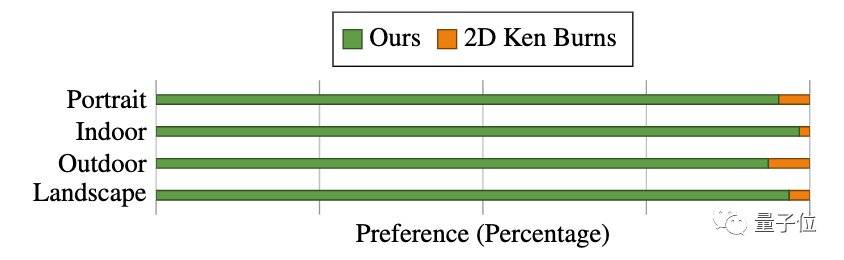
在志愿者们看来,不论是从效果上,还是易用性上,这个新工具显然好得多。
来自Adobe的实习生(现已转Google)
这项研究的第一作者,是一名波特兰州立大学的博士生,名为Simon Niklaus,研究方向为计算机视觉与深度学习。
他在Adobe Research实习的时候完成了这项工作,目前他正在Google实习。

他的博士生导师,名为Feng Liu,博士毕业于威斯康辛大学麦迪逊分校,现在是波特兰州立大学的助理教授,也是这一研究的做作者之一。
此外,这项研究还有另外两名作者,分别是Long Mai和Jimei Yang,都是研究科学家。
SimonNiklaus在HackerNews上与网友互动时也谈到了研究的开源计划。
他说,自己计划公布代码以及数据集,但还没有得到批准。因为这项工作是“实习生”完成的,目前这个算法也是开源的。
当然,这也无法排除他们商业化的可能性,如果你对这一研究感兴趣,可以先看下研究论文:
3DKenBurnsEffectfromaSingleImagehttps://arxiv.org/abs/1909.05483
Onemorething……
关于KenBurnsEffect,也有一段乔布斯的往事。
为了将这一特效用到苹果中,乔布斯还专程联系了KenBurns,希望能够得到他的许可。
一开始,Burns是拒绝的,他不想自己的名字被商业化。
但后来,Burns透露,他同意了乔布斯的请求。
这中间到底发生了什么,也没有太多信息传递出来。
现在,这一效应在iPhone中应用非常广泛,比如照片的“回忆”功能,就能够自动利用这一特效,把一张张照片制作成视频。
这也给Burns带来了很多“麻烦”。
他说,有时候自己走在街上,会有陌生人冲到他面前,说自己如何在iPhone上使用它,或者是问他问题。
对于这种情况,他说自己都是尽力快速逃离现场,跟明星遇上私生饭差不多。
 居小桃 ·
量子位
·
2019-09-16 20:05:29
居小桃 ·
量子位
·
2019-09-16 20:05:29
 评论
评论 分享
分享